Table of contents
- Generalization to Novel Objects, Colors, and Shapes
- Generalization to Novel Colors and Shapes
- How many Demonstrations is Language Worth?
Generalization to Novel Objects, Colors, and Shapes
 | 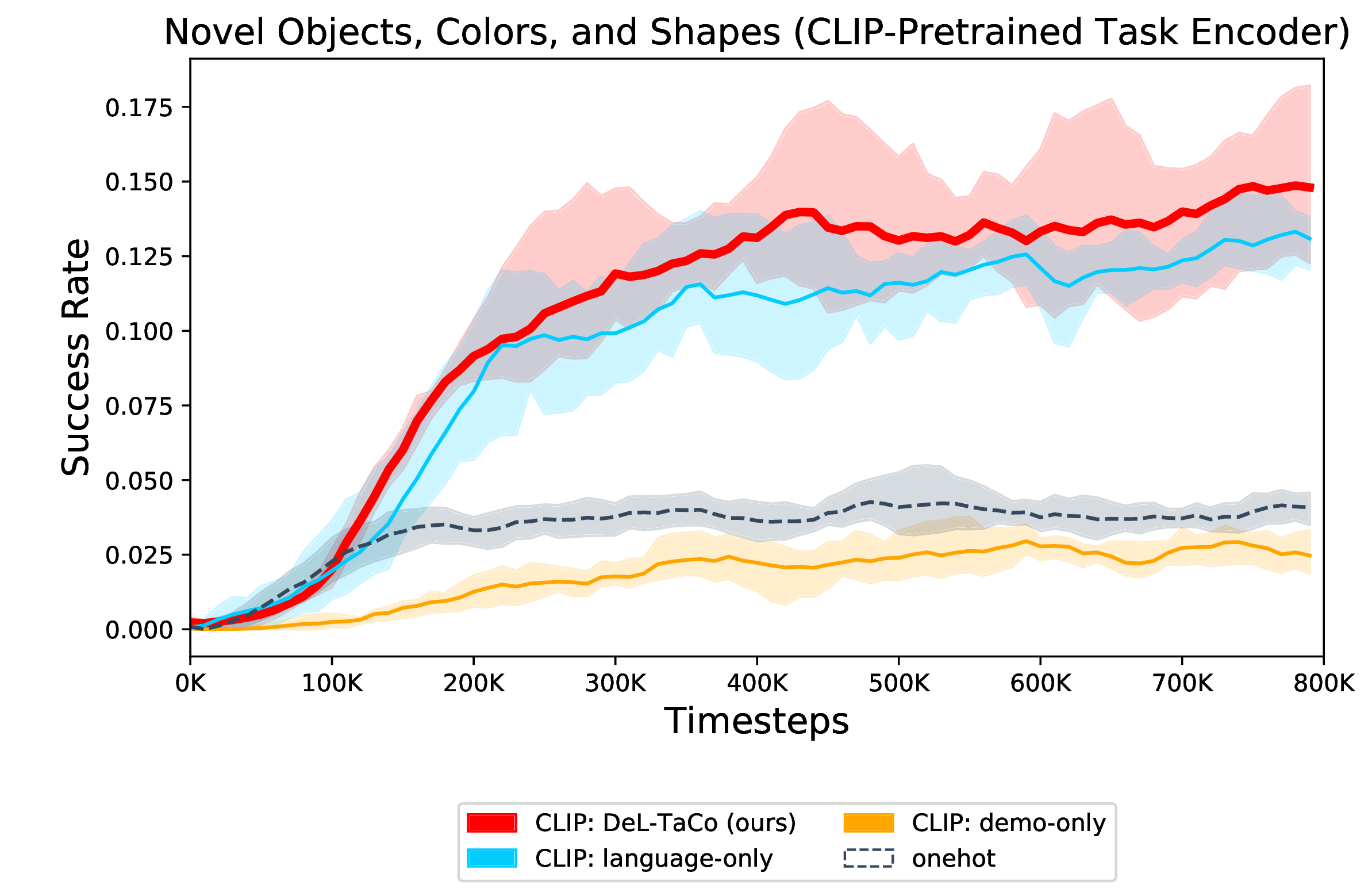 |
| Training a demo encoder from scratch and using pretrained DistilBERT as the language encoder. DeL-TaCo (red) achieves 2-3x the generalization performance of SOTA prior works BC-Z (Jang, et al) and MCIL (Lynch, et al). DeL-TaCo also achieves better generalization performance than policies conditioned on language-only (blue) or demonstration-only (orange), getting closer to the performance of the one-hot oracle policy which was given access to all of the test tasks during training. | Using pretrained CLIP for the language and demonstration encoder, we still see value in task-conditioning with both demonstrations and language with DeL-TaCo (red) than by learning novel tasks with language alone (blue) or demonstration alone (orange). |

Generalization to Novel Colors and Shapes
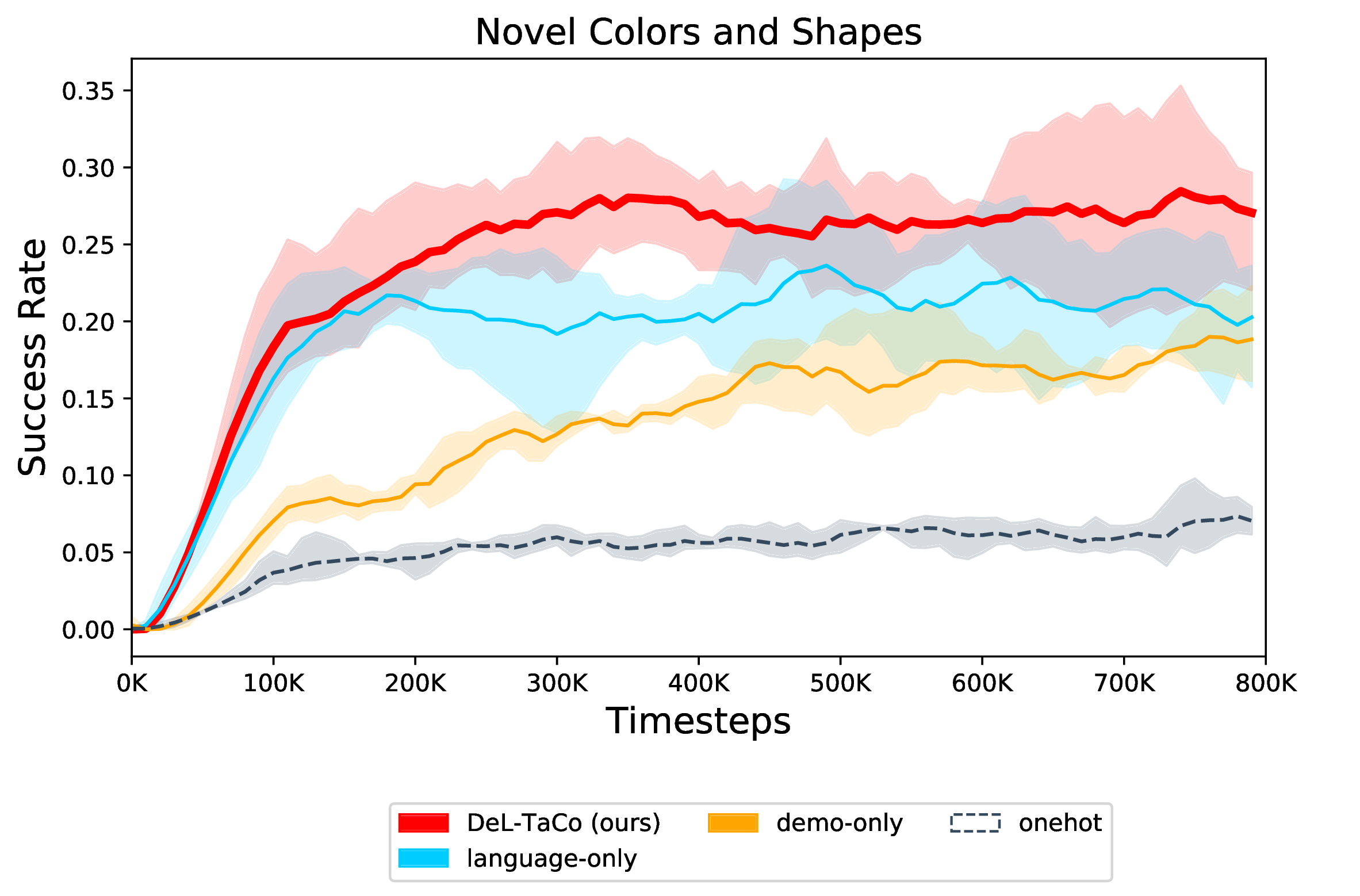
When trained on all 32 objects and evaluated on only the test colors and shapes, DeL-TaCo outperforms language-only and demonstration-only policies by a 5-11% margin. Here, we train the demonstration encoder from scratch and use DistilBERT as the language encoder.

How many Demonstrations is Language Worth?

To evaluate the value of training policies conditioned on both demonstrations and language, we finetune the demonstration-only policy on k demonstrations per test task, where k is indicated in the legend, and compare it to the performance of DeL-TaCo (red dotted line) which was not given access to any demonstration on any test task. We find that the demonstration-only policy only starts to match the performance of DeL-TaCo when trained on 50 demonstrations per test task, showing the tremendous value of learning novel tasks with both language and demonstrations. This demonstrates that in situations where demonstrations are collected in environments that do not perfectly align with the environment the robot is evaluated in, providing both demonstrations and language to specify new tasks requires substantially less teacher effort than specifying tasks with either modality alone.
